1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
| import os
import sys
import cv2
import logging
import numpy as np
def logger_init():
'''
自定义python的日志信息打印配置
:return logger: 日志信息打印模块
'''
logger = logging.getLogger("PedestranDetect")
formatter = logging.Formatter('%(asctime)s %(levelname)-8s: %(message)s')
console_handler = logging.StreamHandler(sys.stdout)
console_handler.formatter = formatter
logger.addHandler(console_handler)
logger.setLevel(logging.INFO)
return logger
def load_data_set(logger):
'''
导入数据集
:param logger: 日志信息打印模块
:return pos: 正样本文件名的列表
:return neg: 负样本文件名的列表
:return test: 测试数据集文件名的列表。
'''
logger.info('Checking data path!')
pwd = os.getcwd()
logger.info('Current path is:{}'.format(pwd))
pos_dir = os.path.join(pwd, 'Positive')
if os.path.exists(pos_dir):
logger.info('Positive data path is:{}'.format(pos_dir))
pos = os.listdir(pos_dir)
logger.info('Positive samples number:{}'.format(len(pos)))
neg_dir = os.path.join(pwd, 'Negative')
if os.path.exists(neg_dir):
logger.info('Negative data path is:{}'.format(neg_dir))
neg = os.listdir(neg_dir)
logger.info('Negative samples number:{}'.format(len(neg)))
test_dir = os.path.join(pwd, 'TestData')
if os.path.exists(test_dir):
logger.info('Test data path is:{}'.format(test_dir))
test = os.listdir(test_dir)
logger.info('Test samples number:{}'.format(len(test)))
return pos, neg, test
def load_train_samples(pos, neg):
'''
合并正样本pos和负样本pos,创建训练数据集和对应的标签集
:param pos: 正样本文件名列表
:param neg: 负样本文件名列表
:return samples: 合并后的训练样本文件名列表
:return labels: 对应训练样本的标签列表
'''
pwd = os.getcwd()
pos_dir = os.path.join(pwd, 'Positive')
neg_dir = os.path.join(pwd, 'Negative')
samples = []
labels = []
for f in pos:
file_path = os.path.join(pos_dir, f)
if os.path.exists(file_path):
samples.append(file_path)
labels.append(1.)
for f in neg:
file_path = os.path.join(neg_dir, f)
if os.path.exists(file_path):
samples.append(file_path)
labels.append(-1.)
labels = np.int32(labels)
labels_len = len(pos) + len(neg)
labels = np.resize(labels, (labels_len, 1))
return samples, labels
def extract_hog(samples, logger):
'''
从训练数据集中提取HOG特征,并返回
:param samples: 训练数据集
:param logger: 日志信息打印模块
:return train: 从训练数据集中提取的HOG特征
'''
train = []
logger.info('Extracting HOG Descriptors...')
num = 0.
total = len(samples)
for f in samples:
num += 1.
logger.info('Processing {} {:2.1f}%'.format(f, num/total*100))
hog = cv2.HOGDescriptor((64,128), (16,16), (8,8), (8,8), 9)
img = cv2.imread(f, 1)
img = cv2.resize(img, (64,128))
descriptors = hog.compute(img)
logger.info('hog feature descriptor size: {}'.format(descriptors.shape))
train.append(descriptors)
train = np.float32(train)
train = np.resize(train, (total, 3780))
return train
def get_svm_detector(svm):
'''
导出可以用于cv2.HOGDescriptor()的SVM检测器,实质上是训练好的SVM的支持向量和rho参数组成的列表
:param svm: 训练好的SVM分类器
:return: SVM的支持向量和rho参数组成的列表,可用作cv2.HOGDescriptor()的SVM检测器
'''
sv = svm.getSupportVectors()
rho, _, _ = svm.getDecisionFunction(0)
sv = np.transpose(sv)
return np.append(sv, [[-rho]], 0)
def train_svm(train, labels, logger):
'''
训练SVM分类器
:param train: 训练数据集
:param labels: 对应训练集的标签
:param logger: 日志信息打印模块
:return: SVM检测器(注意:opencv的hogdescriptor中的svm不能直接用opencv的svm模型,而是要导出对应格式的数组)
'''
logger.info('Configuring SVM classifier.')
svm = cv2.ml.SVM_create()
svm.setCoef0(0.0)
svm.setDegree(3)
criteria = (cv2.TERM_CRITERIA_MAX_ITER + cv2.TERM_CRITERIA_EPS, 1000, 1e-3)
svm.setTermCriteria(criteria)
svm.setGamma(0)
svm.setKernel(cv2.ml.SVM_LINEAR)
svm.setNu(0.5)
svm.setP(0.1)
svm.setC(0.01)
svm.setType(cv2.ml.SVM_EPS_SVR)
logger.info('Starting training svm.')
svm.train(train, cv2.ml.ROW_SAMPLE, labels)
logger.info('Training done.')
pwd = os.getcwd()
model_path = os.path.join(pwd, 'svm.xml')
svm.save(model_path)
logger.info('Trained SVM classifier is saved as: {}'.format(model_path))
return get_svm_detector(svm)
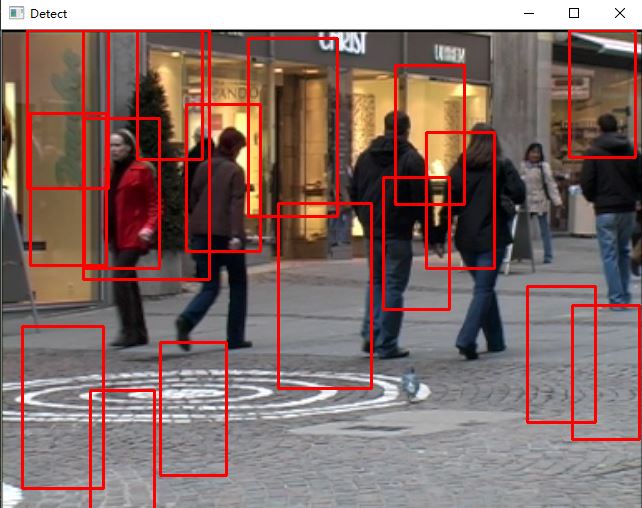
def test_hog_detect(test, svm_detector, logger):
'''
导入测试集,测试结果
:param test: 测试数据集
:param svm_detector: 用于HOGDescriptor的SVM检测器
:param logger: 日志信息打印模块
:return: 无
'''
hog = cv2.HOGDescriptor()
hog.setSVMDetector(svm_detector)
pwd = os.getcwd()
test_dir = os.path.join(pwd, 'TestData')
cv2.namedWindow('Detect')
for f in test:
file_path = os.path.join(test_dir, f)
logger.info('Processing {}'.format(file_path))
img = cv2.imread(file_path)
rects, _ = hog.detectMultiScale(img, winStride=(4,4), padding=(8,8), scale=1.05)
for (x,y,w,h) in rects:
cv2.rectangle(img, (x,y), (x+w,y+h), (0,0,255), 2)
cv2.imshow('Detect', img)
c = cv2.waitKey(0) & 0xff
if c == 27:
break
cv2.destroyAllWindows()
if __name__ == '__main__':
logger = logger_init()
pos, neg, test = load_data_set(logger=logger)
samples, labels = load_train_samples(pos, neg)
train = extract_hog(samples, logger=logger)
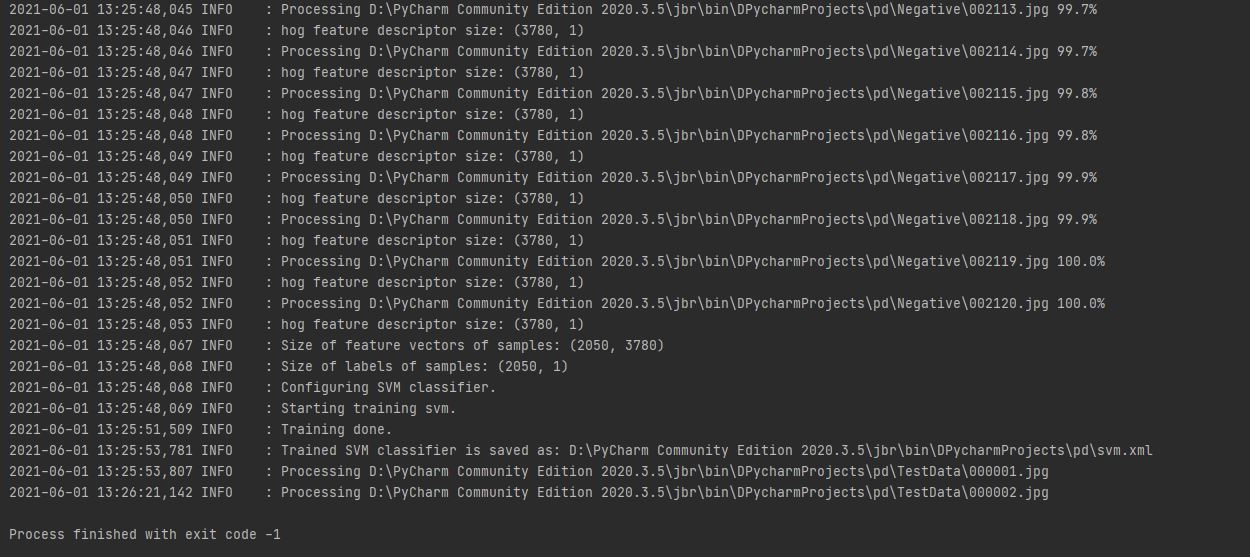
logger.info('Size of feature vectors of samples: {}'.format(train.shape))
logger.info('Size of labels of samples: {}'.format(labels.shape))
svm_detector = train_svm(train, labels, logger=logger)
test_hog_detect(test, svm_detector, logger)
|