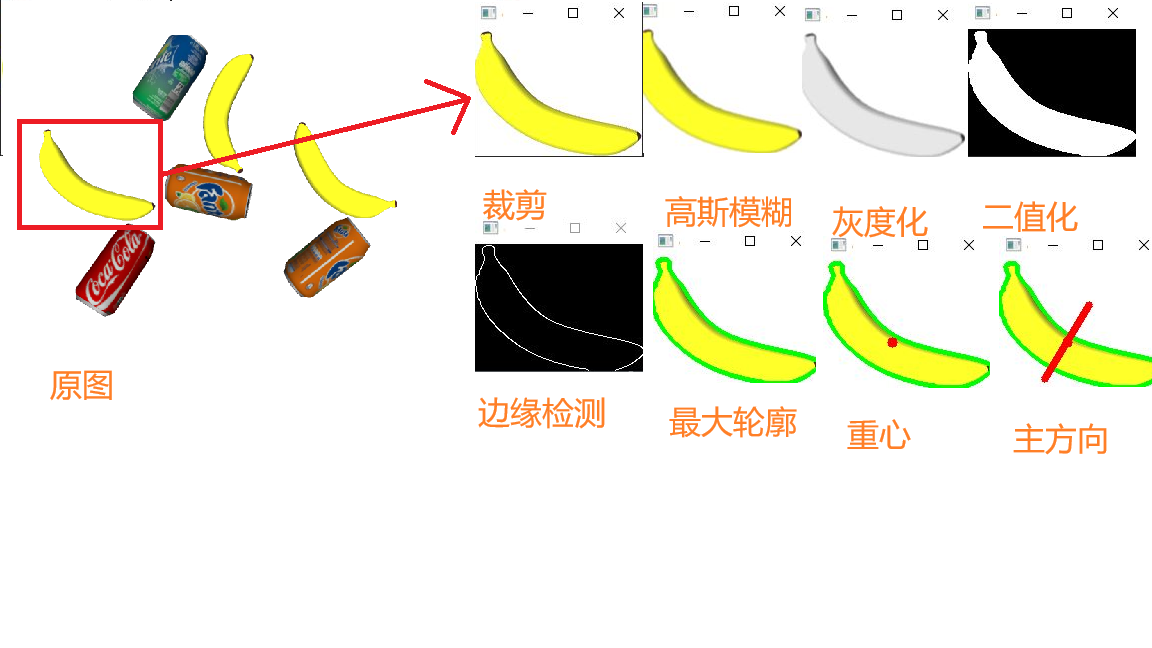
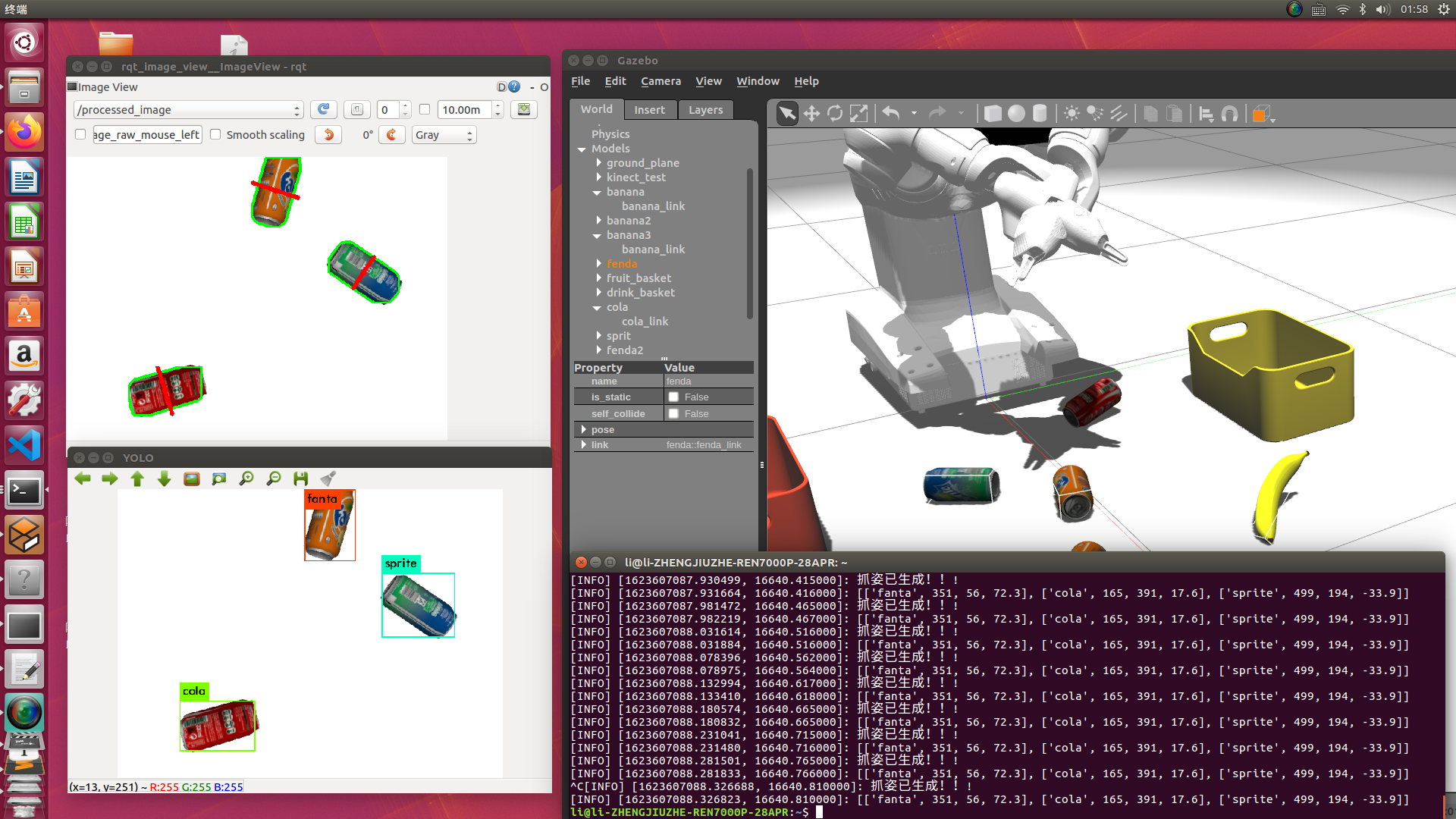
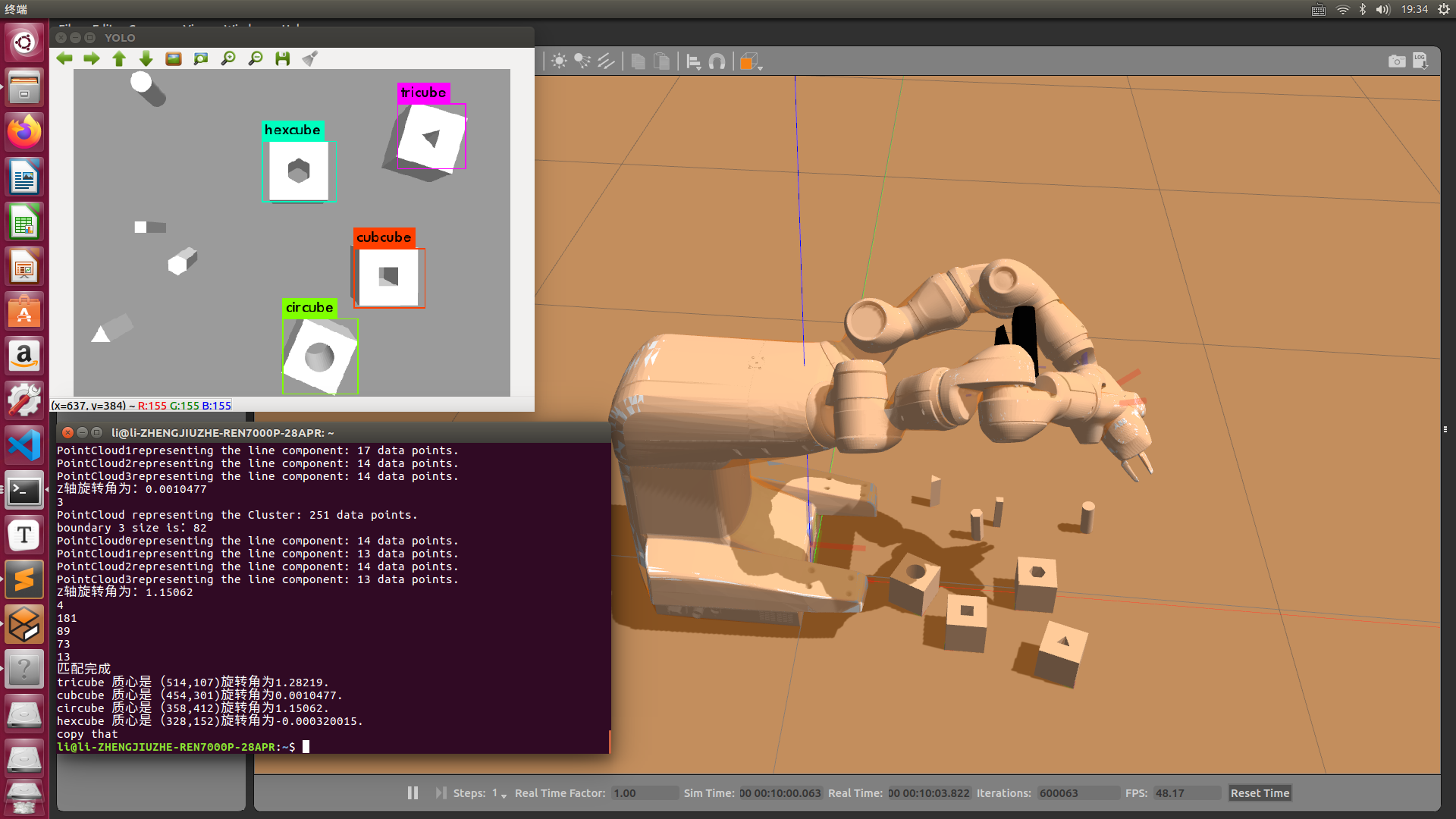
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
|
import rospy
import cv2
import math
import cv_bridge
import numpy as np
import message_filters
from sensor_msgs.msg import Image
from darknet_ros_msgs.msg import BoundingBoxes
from darknet_ros_msgs.msg import ObjectCount
import message_filters
from cv_bridge import CvBridge, CvBridgeError
def find_pose(contour, flag):
mu = cv2.moments(contour, flag)
x = mu['m10'] / mu['m00']
y = mu['m01'] / mu['m00']
a = mu['m20'] / mu['m00'] - x * x
b = mu['m11'] / mu['m00'] - x * y
c = mu['m02'] / mu['m00'] - y * y
Angle = math.atan2(2 * b, (a - c)) / 2
return x, y, Angle
def draw_grasp_line(image2, w, h, x, y, ang):
h = 1.3 * h
ver_ang = (90 - abs(ang)) * math.pi / 180
if w < h:
w, h = h, w
sin_ver_ang = math.sin(ver_ang)
cos_ver_ang = math.cos(ver_ang)
if ang < 0:
A_x = int(x - cos_ver_ang * h / 2)
B_x = int(x + cos_ver_ang * h / 2)
A_y = int(y + sin_ver_ang * h / 2)
B_y = int(y - sin_ver_ang * h / 2)
else:
A_x = int(x - cos_ver_ang * h / 2)
B_x = int(x + cos_ver_ang * h / 2)
A_y = int(y - sin_ver_ang * h / 2)
B_y = int(y + sin_ver_ang * h / 2)
A = (A_x, A_y)
B = (B_x, B_y)
cv2.line(image2, A, B, (0, 0, 255), 5, 8)
return
def img_proc(image, position_list):
img_proc_list = []
for i in range(len(position_list)):
img = image[position_list[i][2]:position_list[i][4],position_list[i][1]: position_list[i][3]]
img2 = cv2.GaussianBlur(img, (3, 3), 0)
img3 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
retval, img4 = cv2.threshold(img3, 232, 255, cv2.THRESH_BINARY_INV)
binary,contours, hierarchy = cv2.findContours(img4, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
n = len(contours)
contours_area = []
for j in range(len(contours)):
contours_area.append(cv2.contourArea(contours[j]))
max_id = np.argmax(np.array(contours_area))
cv2.drawContours(img, contours, max_id, (0, 255, 0), 3)
center_x, center_y, angle = find_pose(contours[max_id], False)
inverse_angle2 = -round(angle * 180 / math.pi, 1)
int_center_x = int(center_x)
int_center_y = int(center_y)
cv2.circle(img, (int_center_x, int_center_y), 5, (0, 0, 255), -1)
min_rect = cv2.minAreaRect(contours[max_id])
min_rect_height = int(min_rect[1][1])
min_rect_width = int(min_rect[1][0])
draw_grasp_line(img, min_rect_width, min_rect_height, int_center_x, int_center_y, inverse_angle2)
int_center_x = int_center_x + int(position_list[i][1])
int_center_y = int_center_y + int(position_list[i][2])
img_proc_list.append([position_list[i][0], int_center_x, int_center_y, inverse_angle2])
return img_proc_list,image
def multi_callback(subscriber_bounding, subscriber_image):
detected_list=[]
bridge= cv_bridge.CvBridge()
cv_image = bridge.imgmsg_to_cv2(subscriber_image, "bgr8")
frame = np.array(cv_image, dtype=np.uint8)
for i in range(len(subscriber_bounding.bounding_boxes)):
detected_list.append([subscriber_bounding.bounding_boxes[i].Class,subscriber_bounding.bounding_boxes[i].xmin,
subscriber_bounding.bounding_boxes[i].ymin,subscriber_bounding.bounding_boxes[i].xmax,subscriber_bounding.bounding_boxes[i].ymax])
detected_result,detected_image=img_proc(cv_image, detected_list)
ros_image=bridge.cv2_to_imgmsg(detected_image, "bgr8")
image_pub.publish(ros_image)
rospy.loginfo("抓姿已生成!!!")
rospy.loginfo(detected_result)
if __name__ == '__main__':
try:
rospy.init_node("darknet_msgs_proc")
rospy.loginfo("开始测试消息订阅....")
image_pub=rospy.Publisher('/processed_image',Image,queue_size = 1)
subscriber_bounding = message_filters.Subscriber('/darknet_ros/bounding_boxes', BoundingBoxes, queue_size=1)
subscriber_image = message_filters.Subscriber('/camera/color/image_raw', Image,queue_size=1)
sync = message_filters.ApproximateTimeSynchronizer([subscriber_bounding, subscriber_image],10,1)
sync.registerCallback(multi_callback)
rospy.spin()
except KeyboardInterrupt:
print("KeyboardInterrupt")
cv2.destroyAllWindows()
|